得益于GCD提供的队列和分发机制,我们将很多原本需要新建线程,用各种锁来同步的事情甩给了GCD来完成,达到了业务层面 Lock-Free 编程的目的(GCD本身是用了一些信号量等锁操作的)。我们也可以选择自己建NSThread来管理线程和线程同步,本文主要介绍底层有哪些同步机制,以及它们具体是怎么实现的。
Mach下最底层的锁
在osfmk/arm/locks.h里,定义了三种底层的锁:spin lock, mutex和rw_lock。对这三个种锁宽泛的定义已经是老生常谈的内容了,这里先主要介绍一下它们在mach中的具体结构,后续再以mutex为例详解具体实现。
Spin Lock 自旋锁
自旋锁是一个忙等待的锁,简单来讲就是如果其他线程已加锁,自身线程用一个死循环来判断对方是否已解锁。由于线程会处于忙等待状态,所以自旋锁不适合被锁住过长时间。自旋锁在osfmk/arm/locks.h中的定义如下:
typedef struct {
struct hslock hwlock;
uintptr_t type;
} lck_spin_t;
其中type指明了锁的类型,如LCK_SPIN_TYPE等。而hslock是最底层的锁,定义在osfmk/arm/hw_lock_types.h中:
struct hslock {
uintptr_t lock_data;
};
typedef struct hslock hw_lock_data_t, *hw_lock_t;
其中lock_data可以用来存储额外的数据,一般用于存储锁的状态。hslock提供了最基础的lock,unlock,try,held等操作,被具体应用在自旋锁的加锁解锁等操作中,后面会具体介绍一部分。
Mutex 互斥锁
互斥锁是比较常用的锁,如果一个线程在请求互斥锁时,其他线程已经加锁,那么该线程就会进入睡眠状态,直到后续线程解锁将其唤醒,这里要注意的是同一个线程如果请求两次互斥锁的话,会触发一个内核异常。结构体定义如下:
typedef struct _lck_mtx_ {
union {
uintptr_t lck_mtx_data; /* Thread pointer plus lock bits */
uintptr_t lck_mtx_tag; /* Tag for type */
};
union {
struct {
uint16_t lck_mtx_waiters;/* Number of waiters */
uint8_t lck_mtx_pri; /* Priority to inherit */
uint8_t lck_mtx_type; /* Type */
};
struct {
struct _lck_mtx_ext_ *lck_mtx_ptr; /* Indirect pointer */
};
};
} lck_mtx_t;
可以看到它主要由两部分组成,第一部分是data或者tag,用于存储状态或者类型等数据。第二部分是用于存储与该互斥锁相关的等待着信息,包括等待着的数量,优先级,类型等,用于unlock时唤醒判断。但是这里只存储了数量等参数信息,真正的锁序列是直接以run queue的形式存储在thread结构体中的。这里有两个与解锁相关比较关键的宏定义:
#define LCK_MTX_EVENT(lck) ((event_t)(((unsigned int*)(lck))+((sizeof(lck_mtx_t)-1)/sizeof(unsigned int))))
#define LCK_EVENT_TO_MUTEX(event) ((lck_mtx_t *)(uintptr_t)(((unsigned int *)(event)) - ((sizeof(lck_mtx_t)-1)/sizeof(unsigned int))))
在mutex解锁的过程中,是通过发送mutex消息来完成唤醒其他线程的,这里有一个mutex与event相互转化的过程,可以看到lck_mtx_t这个结构体是以unsinged int对齐的,这里用lck_mtx_t的大小-1除以unsinged int的大小,就是指向了这个结构体的最后一个padding,而第二个union两个struct都正好只占一个padding,也就正好指向了第二个uinon部分。也就是说这是一个指向跟结构体和第二个结构体之间的指针转移操作,也是内核代码中常见骚操作之一。(满脑子都是骚操作.jpg)
R_W Lock 读写锁
读写锁是用来保证同时读,单独改的锁,也就是允许多个线程同时执行读操作,但是写操作同时只有一个线程可以执行,并且要在所有已发生的读写操作完成之后才能进行,相对应的这里读写锁提供了两个加锁方法:shaed和exclusive。
读写锁的概念与GCD中队列任务屏障以及接下来讲的内存屏障十分相似,但是GCD是面向队列的,CPU内存屏障是面向过程的。读写锁的结构体中主要定义了一些状态,flag字段等,具体可以在locks.h中查看。
锁的具体实现
接下来就以mutex(互斥锁)为例详细介绍下锁的实现,不过在看具体源码之前,需要了解一些基础的原子操作知识,首先看一下在locks_arm中几个关键的定义:
#define memory_barrier() __c11_atomic_thread_fence(memory_order_acq_rel_smp)
#define load_memory_barrier() __c11_atomic_thread_fence(memory_order_acquire_smp)
#define store_memory_barrier() __c11_atomic_thread_fence(memory_order_release_smp)
// Enforce program order of loads and stores.
#define ordered_load(target, type) \
__c11_atomic_load((_Atomic type *)(target), memory_order_relaxed)
#define ordered_store(target, type, value) \
__c11_atomic_store((_Atomic type *)(target), value, memory_order_relaxed)
这里分别定义了读写内存壁垒,顺序读写等一些过程,是所有锁的基础,用到了atomic_thread_fence,atomic_load,atomic_store等操作。这里不可避免得要先从编译阶段到应用层来介绍Memory Order:
编译阶段的指令重排
我们写这样一段简单的代码,用普通编译和开启编译优化的命令分别编译:

可以看到B的赋值操作在两段汇编代码中的位置是不一样的,因为开启编译优化后,编译器为了达到节约寄存器的使用,减少操作指令之类的目的,会根据情况调整指令,或者进行指令重排之类的操作。如果在代码中因为自身业务原因希望避免这样的指令重排,我们在locks_arm.c中有如下一个定义:
// Prevent the compiler from reordering memory operations around this
#define compiler_memory_fence() __asm__ volatile ("" ::: "memory")
这是GCC提供的其中一种编译阶段内存壁垒(同时包含读写的壁垒),可以保证该行前后的读和写操作不会越过这个壁垒,保证前后两个部分的相对有序(每个部分内还是可以重排)。
C++中的内存顺序和原子操作
C++中提供了一系列原子操作的接口,其中最常用的是atomic_load和atomic_store
template< class T >
T atomic_load_explicit( const std::atomic<T>* obj,
std::memory_order order ) noexcept;
void atomic_store_explicit( std::atomic<T>* obj,
typename std::atomic<T>::value_type desr,
std::memory_order order) noexcept;
顾名思义,这是对一个操作对象的原子存和原子读操作,除了指定操作对象和目标对象之外,这里还提供了一个具体的std::memory_order参数,代表可以指定的具体内存顺序规则,在锁相关的代码中主要用到了以下两种:
(1)Acquire/Release
这是一个对应多线程下保证某一个变量读写有序的规则。即acquire用于读(#LoadStore和#LoadLoad,保证后序读写操作都在这个load操作后进行),Release用于写(#LoadStore和#StoreStore,保证前序读写操作都在这个store操作前进行)。关于这个,这篇文章讲述得非常清楚了,引用一张图:

(2)memory_order_relaxed
松弛的内存顺序,只保证在一个线程内,读写操作不能被重新排序,但是多个线程的无法保证。
完整的定义可以看:https://gcc.gnu.org/wiki/Atomic/GCCMM/AtomicSync 。这里就不重复阐述了,里面讲的十分细致和完整。
Mutex的加锁和解锁过程
这里我们以mutex为例详细看下加锁和解锁过程。首先,这里加锁需要简单分为两个部分:对lck变量本身的锁(防止同时访问lck)以及mutex锁本身。
(1)对lck变量的锁:interlock
interlock是啥呢,话不多说,直接看interlock的宏定义:
#define interlock_lock(lock) hw_lock_bit ((hw_lock_bit_t*)(&(lock)->lck_mtx_data), LCK_ILOCK_BIT)
interlock其实就是把lock的lck_mtx_data调用hw_lock_bit设置成LCK_ILOCK_BIT(这个变量是0)。hw_lock_bit从功能上来讲,很好理解,它是一个把一个变量用类似spinlock的方式设置成对应的值,但是必须是自己设的。(举个例子,目标把变量a设置成1,如果设置的时候发现a已经是1了,说明有其他操作把它持有了,一直等到a!=1或者超时的时候,再设置a=1)。具体流程如下:
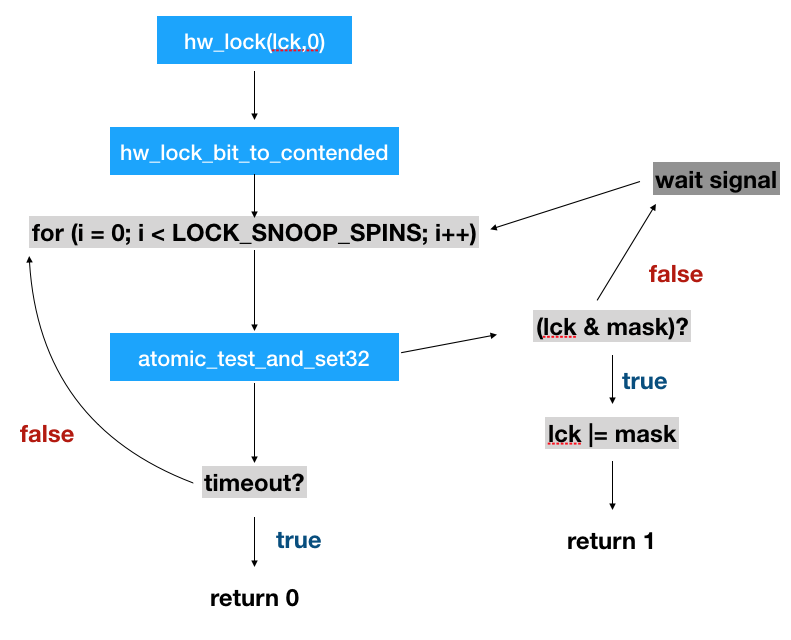
通过hw_lock_bit,可以防止两个线程同时对lock进行操作,防止加锁过程被打断等。要注意这里只是保证lock变量在加解锁过程中不被打断。
(2)Mutex锁
Mutex的核心加锁过程主要在lck_mtx_lock_contended中:
for ( ; ; ) {
if (atomic_compare_exchange(&lock->lck_mtx_data, 0, LCK_MTX_THREAD_TO_STATE(thread),memory_order_acquire_smp, FALSE))
return;
interlock_lock(lock);
interlock_held:
state = ordered_load_mtx(lock);
holding_thread = LCK_MTX_STATE_TO_THREAD(state);
if (holding_thread == NULL)
break;
ordered_store_mtx(lock, (state | LCK_ILOCK | ARM_LCK_WAITERS)); // Set waiters bit and wait
lck_mtx_lock_wait(lock, holding_thread);
}
主要过程如下:
- 放一个死循环,首先在这个死循环中首先用interlock将lock变量加锁。
- 从lock的
lck_mtx_data中取出state。 - 将state转换为thread,检测当前是否有线程持有了这个锁。
- 如果持有了锁,直接break,进行接下来的加锁操作(接下来就是设置lock的state之类的)
- 如果有线程已经持有,那么执行wait操作,等待唤醒。(这一步后面详细介绍)
这里有两个重要的概念,state和thread,他们是可以相互转换的:
/*
* Lock state to thread pointer
* Clear the bottom bits
*/
#define LCK_MTX_STATE_TO_THREAD(s) (thread_t)(s & ~(LCK_ILOCK | ARM_LCK_WAITERS))
/*
* Thread pointer to lock state
* arm thread pointers are aligned such that the bottom two bits are clear
*/
#define LCK_MTX_THREAD_TO_STATE(t) ((uintptr_t)t)
thread_t是一个unsinged int,由于线程创建时的指针是内存对齐的,所以最后两个bit可以被用于存储当前的状态,state转换为thread指针只要将最后两位置0就是指针的地址。
lck_mtx_lock_wait是加锁过程中最重要的一步,函数中首先是设置holding线程的调度优先级,然后修改了基本属性(如mutex中waiter是变量加1等),最终调用了thread_block函数将线程挂起。而与lck_mtv_lock_wait相对应的,是在解锁过程中调用的lck_mtx_unlock_wakeup函数:
/*
* Invoked on unlock when there is contention.
* Called with the interlock locked.
*/
void
lck_mtx_unlock_wakeup (lck_mtx_t *lck, thread_t holder)
{
thread_t thread = current_thread();
lck_mtx_t *mutex;
//xxxxx….
assert(mutex->lck_mtx_waiters > 0);
if (mutex->lck_mtx_waiters > 1)
thread_wakeup_one_with_pri(LCK_MTX_EVENT(lck), lck->lck_mtx_pri);
else
thread_wakeup_one(LCK_MTX_EVENT(lck));
if (thread->promotions > 0) {
spl_t s = splsched();
thread_lock(thread);
if (--thread->promotions == 0 && (thread->sched_flags & TH_SFLAG_PROMOTED))
lck_mtx_clear_promoted(thread, trace_lck);
thread_unlock(thread);
splx(s);
}
//xxxx….
}
可以看到当mutex->lck_mtx_waiters数量大于1或者等于1时,分别调用了thread_wakeup_one_with_pri和thread_wakeup_one来从运行队列中根据优先级等来唤醒对应的线程。可以看到这里用到了前面介绍的LCK_MTX_EVENT来将lck转换为mutex消息。这里最终会走到waitq_wakeup64_one_locked中调用thread_go来唤醒下一个待解锁的线程。
总结
原子操作是所有锁和同步的基础,编译阶段GCC提供了编译过程中的内存壁垒,而多线程环境下应对不同的需求可以使用不同程度的内存顺序模型(例如完全顺序一致或者基于acquire和release的等)。
本文简单介绍了locks_arm.c下的三个锁:自旋锁,互斥量和读写锁。自旋锁可以说是无处不在的锁,因为如果要实现例如加锁一个lock变量这种马上就解锁的操作,自旋锁无疑是开销最小的,因此无论是互斥量还是读写锁的实现过程中,都依赖了自旋锁来进行小范围的同步。互斥量的实现依赖了线程调度模块,这里只做了简单介绍,后续有机会详细介绍下。除这三个最底层的锁之外,上面还封装和实现了信号量,递归锁等我们常见的同步模型,以及针对I/O操作的一些锁等等,大部分都是以这里介绍的三种锁为基础搭建的。
最后关于CPU相关的内存知识,强烈推荐一篇能看一年的论文,What Every Programmer Should Know About Memory:https://www.akkadia.org/drepper/cpumemory.pdf (头有点大.jpg)
参考文献:
【1】Darwin-XNU源码:https://github.com/apple/darwin-xnu
【2】GCC Memory Order: https://gcc.gnu.org/wiki/Atomic/GCCMM/AtomicSync
【3】OS X Internals: http://venom630.free.fr/pdf/OSXInternals.pdf
【4】Acquire and Release Semantics: http://preshing.com/20120913/acquire-and-release-semantics/