iOS和Mac OS从顶到下有一系列长长的不同alloc函数,NSObject的alloc和allocWithZone(这里oc层的NSZone已经不使用了),Core Foundation里的CFAllocatorAllocate,libc里的malloc,内核的vm_allocate和kalloc等。今天我们从libc开始,看一下从用户态到内核态的malloc/allocate是怎么工作的。
用户态的Malloc Zone
Memory Zone是一个我们在很多操作系统里面都能见到的一个概念,例如在Linux中有ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM等memory cache,windows中有memory pool,而在Darwin的libmalloc中,以szone_t的形式存在。那么memory zone存在的意义是什么呢?
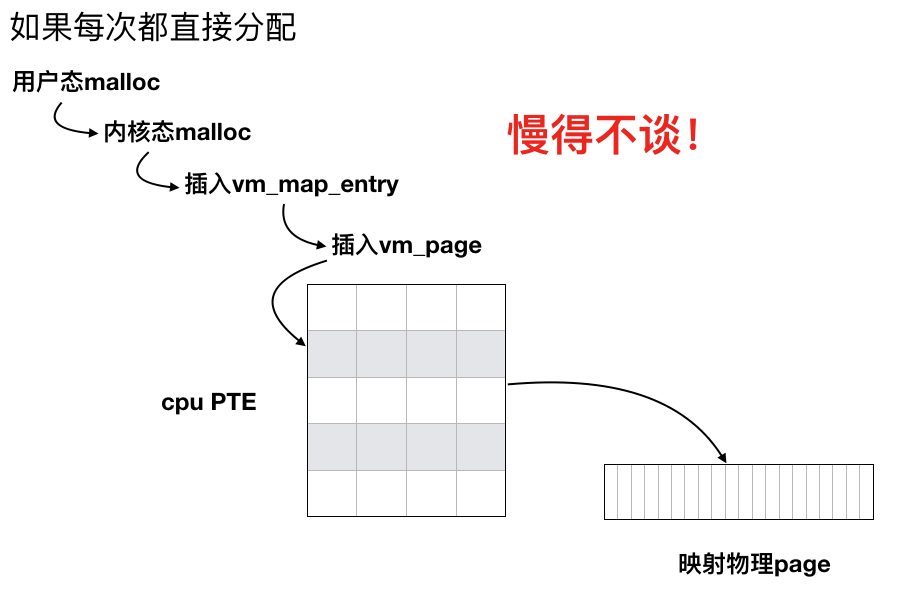
在上一篇讨论虚拟内存中,我们提到进程是建立在虚拟内存的基础之上的,虚拟内存与物理内存通过pmap来建立映射。如果每次进行内存分配,都需要从顶到下走一遍插入虚拟内存页(vm_page),然后通过pmap和不同架构的内存地址映射表来建立映射,会是一件缓慢而痛苦的事情。而memory zone也被称为memory cache,就是一段预先分配好的内存空间,顶层在需要分配内存的时候,直接去zone里面取,按需不足时再构建新的内存映射,达到高效分配等目的。
要注意的是,用户态的libmalloc有szone_t,而内核mach层有mach zone,这两个是完全不同的东西。下面我们详细介绍用户态和内核态的zone,它们之间的联系和具体的作用。
libmalloc中的malloc和szone_t
在libmalloc中,memory zone是在magazine_zone.h中定义的szone_t,该库中的大多数操作都是以这个结构体为基础的。而malloc操作从源码来看,最终是由magazine_malloc.c中的szone_malloc_should_clear函数完成的。首先我们来看几个定义:
#define SHIFT_TINY_QUANTUM 4
#define TINY_QUANTUM (1 << SHIFT_TINY_QUANTUM)
#if MALLOC_TARGET_64BIT
#define NUM_TINY_SLOTS 64 // number of slots for free-lists
#else // MALLOC_TARGET_64BIT
#define NUM_TINY_SLOTS 32 // number of slots for free-lists
#endif // MALLOC_TARGET_64BIT
/*
* The threshold above which we start allocating from the small
* magazines. Computed from the largest allocation we can make
* in the tiny region (currently 1008 bytes on 64-bit, and
* 496 bytes on 32-bit).
*/
#define SMALL_THRESHOLD ((NUM_TINY_SLOTS - 1) * TINY_QUANTUM)
/*
* The threshold above which we start allocating from the large
* "region" (ie. direct vm_allocates). The LARGEMEM size is used
* on systems that have more than 1GB RAM.
*/
#define LARGE_THRESHOLD (15 * 1024)
#define LARGE_THRESHOLD_LARGEMEM (127 * 1024)
对于不同大小的内存,分配方式是不一样的。这里通过SMALL_THRESHOLD和LARGE_THRESHOLD两个阈值将内存分配分成了tiny,small和large三种模式
Tiny内存分配
对小于等于SMALL_THRESHOLD(64位系统下1008字节,32位系统下496)的内存分配,系统会走tiny的内存分配方式。根据之前讲的,memory zone是一块预先分配好的内存,作为szone_t的一部分,在tiny内存分配中,自然是用到若干块预先分配好的内存。
这里用到了一个核心概念“quantum”,一个quantum是内存分配中的最小单位,大小为16个字节,也就是说任何以tiny形式分配的内存都是16字节的倍数。一块预先分配好的内存被均分成了一个个连续的quantum和一个标记使用信息的bitmap,如下图所示:
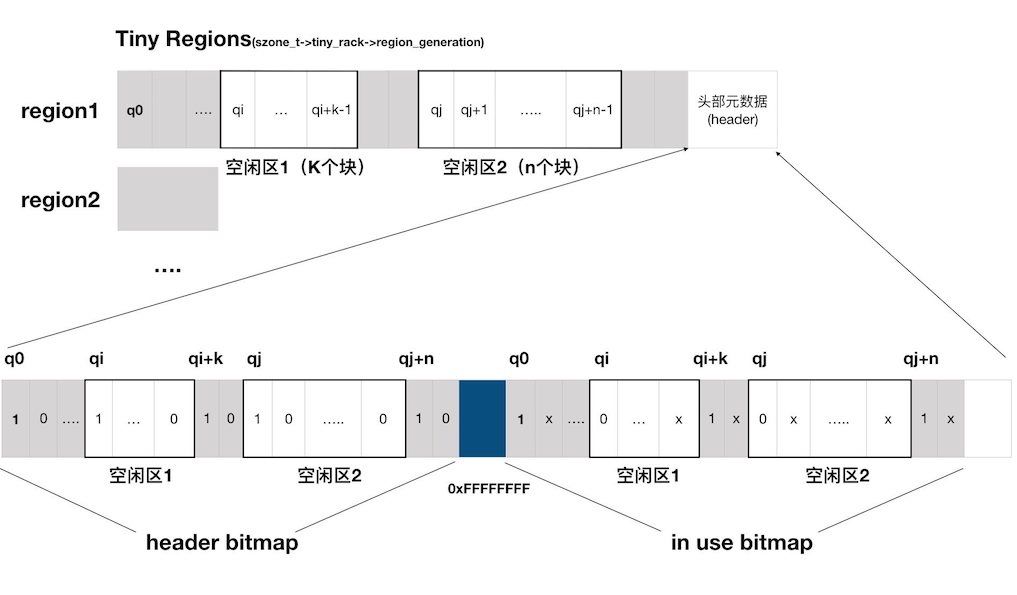
那么我们如何能够确定该块区域中哪些部分是可用的,哪些部分是不可用的呢?主要依赖一个bitmap和如下几条规则:
- 一个完整的bitmap由两个子bitmap(header bitmap和in use bitmap)组成。每个子bitmap的大小为 (一个预先分配好的内存中quantum数量) * 1bit,中间用0xFFFFFFFF分隔。
- 如果一块区域已经被使用,那么这块区域的第一个quantum在header bitmap 和 in use bitmap中对应的值都是1.
- 如果一块区域是空闲的,那么这块区域的第一个quantumheader bitmap 和 in use bitmap中对应的值分别是1和0.
- 其他情况下,quantum在 header bitmap中的值是0.
- 其他情况下,quantum在in use bitmap中对应的值无关紧要,无需额外操作,爱是几就是几。
其实一句话就能总结,header bitmap是用来标记一个块的起始位置的,为1的就是一个块的起始。那么如何区分是已分配还是空闲呢?in use bitmap中为1的就是一个已分配块的起始,如果header bitmap为1,in use bitmap为0就是空闲块的起始。
那么我们以上图为例,阐述下空闲区1是怎么被定位的:
- 从左往右扫描,发现q0在两个bitmap中的值都是1,那么表明q0是一块已使用区域的开始。
- 继续扫描,发现q2到qi-i在header bitmap中的值都是0,说明这是已使用区域的一部分。
- 扫描到qi,发现qi在header bitmap中是1,in use bitmap中是0,说明这是空闲块的起始
- 继续扫。。。。
在此基础之上,连续的quantums组成的空闲块被存储在了一系列链表上,如下图所示:
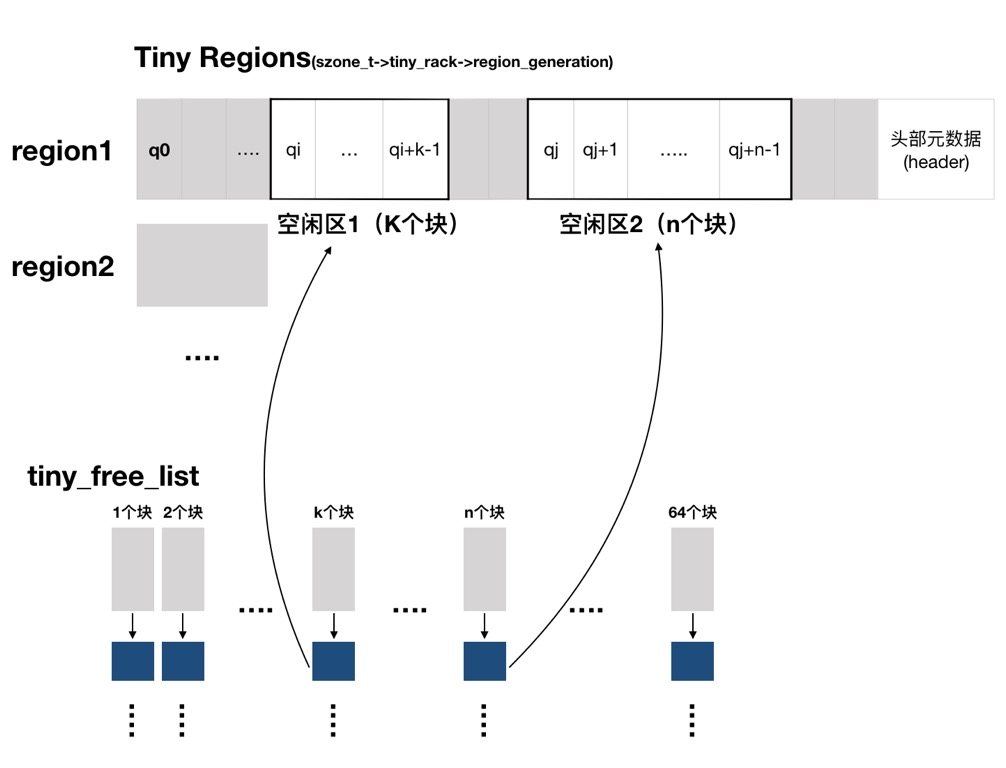
tiny_free_list是一个双向链表,一共有64个元素,每个双向链表中都存储着另一个双向链表。第K个链表中存储的就是所有“连续K个quantum组成的区域”。每次我们需要分配内存的时候,就根据需要分配内存的大小除以每个quantum的大小得到应该需要几个连续的块,找到合适的就分配,整个内存不够分配时就开辟新的region。这里具体的分配算法可以在magazine_tiny.c的tiny_malloc_from_free_list函数中查看。
small内存分配
对于大于SMALL_THRESHOLD,小于等于LARGE_THRESHOLD的内存,就走small内存分配。small内存分配和tiny十分相似,只是每个quantum的大小变了,如下:
#define SHIFT_SMALL_QUANTUM (SHIFT_TINY_QUANTUM + 5) // 9
#define SMALL_QUANTUM (1 << SHIFT_SMALL_QUANTUM) // 512 bytes
另外header bitmap也用了不同的定义,如下:
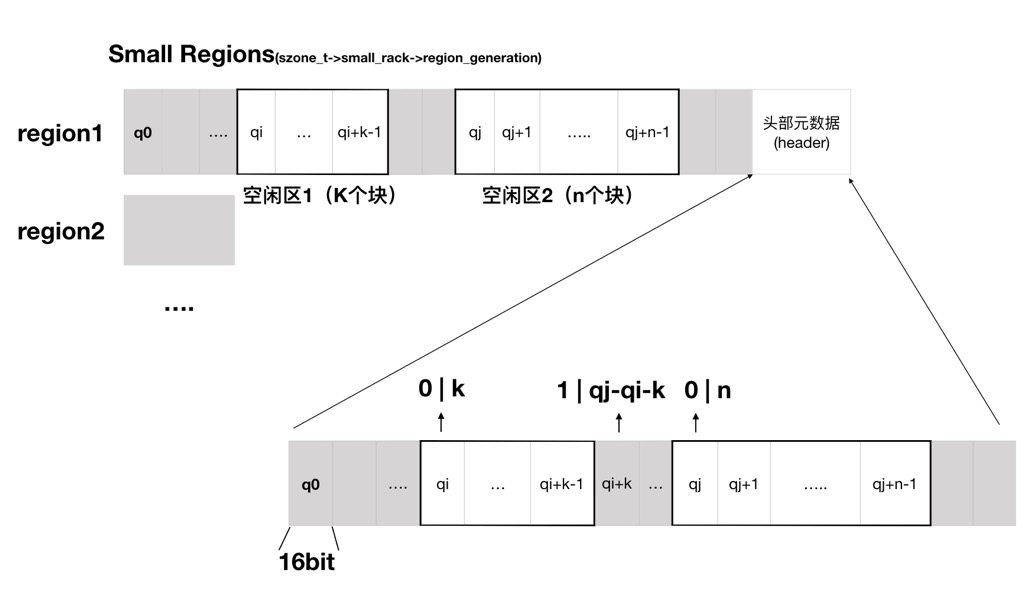
如图所示,每个quantum都映射到了一个16bit的区域上,这16bit被拆分成了两个部分:
- 第1bit代表使用情况,0代表空闲,1代表已分配。
- 后15bit组成的数字代表连续的quantum个数。
| 只有连续区域的第一个quantum被标记,如 0 | k 就代表从该quantum开始,后面连续K个快都是空闲的,非常直观。 |
large内存分配
对于大于LARGE_THRESHOLD的内存,走large内存分配。一块large内存是用一个large_entry_t来描述的:
typedef struct large_entry_s {
vm_address_t address;
vm_size_t size;
boolean_t did_madvise_reusable;
} large_entry_t;
这里就直接操作虚拟内存层的内存分配了,内存分配操作由vm_allocate函数完成,注意这里的address是高地址位的地址,address+size是低地址,由于是通过XNU的vm_allocate来直接分配,这里的其实和终结地址一定是页对齐的。所有的大内存会被根据地址哈希在一个数组里:
large_entry_t *large_entries; // hashed by location; null entries don't count
大内存的整体处理定义在magazine_large.c里,里面还有一些cache相关的操作等,这里就不展开了。
总结
对于不同大小的内存分配,libmalloc采用了tiny,small,large三种分配方式,主要目的是为了
- 更加高效的内存分配。
- 更合理的内存利用率。
由于日常内存分配大部分都会落在tiny和small中,通过预分配内存块,构建free_list等操作,一次内存分配大概率可以通过几次链表操作和几个bit位操作就能完成,避免了每次都构建虚拟内存,映射到物理内存的尴尬场面,在保证高效的前提下,通过quantum分区来尽量保证内存利用率。
本文还只介绍了用户态的malloc,XNU内部虚拟内存的分配,它与用户态之间的联系,用户态memory zone和内核态memory zone之间的关系等,下次继续详细介绍。
参考文献
【1】Darwin-XNU源码:https://github.com/apple/darwin-xnu
【2】Mac OS® X Internals: http://venom630.free.fr/pdf/OSXInternals.pdf
【3】libmalloc源码:https://opensource.apple.com/source/libmalloc/libmalloc-140.40.1/