作为最古老的现代操作系统之一,Mac OS一直是被人们相对讨论得最少的(相比于Linux和Windows)。这里打算开一个系列来具体讲讲Mac OS和iOS(用乔老爷发布会的话说:”We run OS X on iPhone”)内核的一些知识点,内容主要以源码为主,结合官方文档详细介绍操作系统底层的一些内容。这个系列预计会包含可执行文件加载,虚拟内存,线程,boot等。本篇主要介绍一些宏观上架构作为引言,并详细介绍可执行文件的加载过程(特别注意的是Mach-O文件结构和一些运行时的知识实用性和对理解操作系统的帮助作用都很大,但是已经有数不尽优秀的资料可以参考,这部分并不是本篇的重点)。
简单看一下Darwin的架构
iOS和 Mac OS 都是Unix标准的操作系统. 所谓Unix标准,就是按照POSIX (Portable Operating System Interface)标准家族来构建的操作系统,该标准定义了一整套内存,线程,文件,I/O处理等功能的标准接口。iOS的基础系统架构如下:
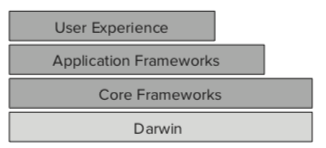
Application Frameworks 和 Core Frameworks是我们这些拖控件工程师接触得最多的部分,苹果在这里提供了一整套十分友好的API来搭建APP。而Darwin处于最底层,提供了最基础的例如线程模型,调度,内存映射和管理等一系列功能,它是Unix操作系统的一个具体实现,稍微详细的结构如下:
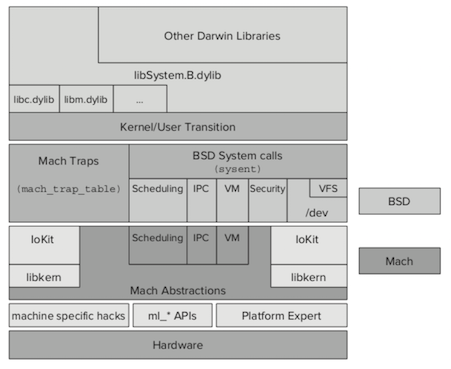
苹果官方把Darwin分成了五个主要的模块:
Mach,主要提供了:
- 虚拟内存
- 进程和线程的底层描述
- 任务调度
- 跨进程通信(IPC)
提供了最底层的处理,管理一些列如CPU,内存等系统资源,为其他模块提供了一个基于消息中心的处理模块。
BSD,主要提供了:
- 文件系统
- 网络
- UNIX安全模型
- BSD进程模型(包括进程ID,信号和相关API等)
- 大部分POSIX标准的API
- pthread以及相关的同步策略
BSD层是建立在Mach之上的,以Mach提供的功能模块为基础搭建的实现了POSIX标准API的一个组件。相比与Mach层,BSD提供了更高层的功能描述,贴合unix的系统设计。
Networking
File Systems
这两个模块顾名思义负责网络和文件系统,属于BSD负责的范畴,是它的子模块。
I/O Kit
负责硬件交互,属于Mach的子模块。
Unix常见可执行文件,fat以及Mach-O
Unix可执行文件的类型是由文件头部的一个uint32_t类型的”magic”字段定义的,Windows下有PE32/PE32+,Linux下有ELF格式的可执行文件,Mach下主要有Universal binaries(fat)和Mach-O两种。
Universal Binaries(fat)
顾名思义,通用的二进制文件,就是在各个不同架构下都可以适配或运行的文件。如何做到通用的就是把不同硬件架构下的文件整合到了一个文件中,我们直接看一下<mach-o/fat.h>里面的定义:
#define FAT_MAGIC 0xcafebabe
#define FAT_CIGAM 0xbebafeca /* NXSwapLong(FAT_MAGIC) */
struct fat_header {
uint32_t magic; /* FAT_MAGIC */
uint32_t nfat_arch; /* number of structs that follow */
};
struct fat_arch {
cpu_type_t cputype; /* cpu specifier (int) */
cpu_subtype_t cpusubtype; /* machine specifier (int) */
uint32_t offset; /* file offset to this object file */
uint32_t size; /* size of this object file */
uint32_t align; /* alignment as a power of 2 */
};
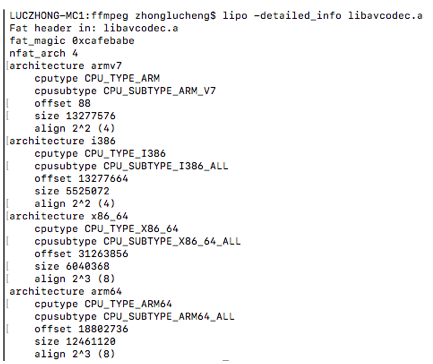
它主要由一个header和若干个fat_arch组成的,header中标明了文件类型(magic)和fat_arch的个数。每个fat_arch标明了对应的cpu类型,在文件内的偏移量和大小等。例如用lipo命令看ffmpeg的libavcodec.a文件,可以看到是四个cpu架构下文件的集合:
Mach-O文件
关于Mach-O文件,可以说是老生常谈的一个话题了,关于分析Mach-O头部,各个段和节的组成以及含义,网上有很多优秀的文章分析,就不在这里重复描述了,完整的定义可以看 https://github.com/aidansteele/osx-abi-macho-file-format-reference(Mach-O Format Reference),以及苹果的官方文档:http://math-atlas.sourceforge.net/devel/assembly/MachORuntime.pdf(Mach-O Runtime Architecture)。后续在介绍虚拟内存,进程等内容的时候会结合Mach-O来分析。
Mach-O加载过程以及地址空间布局随机化(Address Space Layout Randomization)
地址空间布局随机化是通过随机化每次进程启动后各个段,节,堆栈等起始位置,来防止攻击者轻易修改程序的内容(例如修改内存中一个函数指针位置,如果每次加载,进程内各个部分的相对偏移量都是不变的话,就很容易做出通用的hook程序)。
下面我们直接从源码来分析Mach-O文件在load过程中是如何实现地址空间布局的随机化的:
1. load_machfile初始化vm_map和随机偏移量
Mach-O文件的加载会经过初始化镜像,加载镜像到内存,头部检测等过程,然后走到load_machfile开始真正解析文件内容。为了便于理解摘录了部分代码(完整代码可以在mach_loader.c中找到,这里只保留了一小部分并且加上了一些注释,请放心食用)
部分代码:
load_return_t
load_machfile(
struct image_params *imgp,
struct mach_header *header,
thread_t thread,
vm_map_t *mapp,
load_result_t *result
)
{
//xxx….
pmap_t pmap = 0; /* protected by create_map *///用于映射物理地址
vm_map_t map;//虚拟地址
int64_t aslr_page_offset = 0;//随机页偏移量
int64_t dyld_aslr_page_offset = 0;//动态库的随机页偏移量
int64_t aslr_section_size = 0;
int64_t aslr_section_offset = 0;
//xxxx….
//先创建一个映射物理地址的pmap
pmap = pmap_create(get_task_ledger(ledger_task),
(vm_map_size_t) 0,
result->is64bit);
//基于pmap创建一个虚拟地址入口
map = vm_map_create(pmap,
0,
vm_compute_max_offset(result->is64bit),
TRUE);
//xxxxx…
/*
* Compute a random offset for ASLR, and an independent random offset for dyld.
*/
//这里是具体计算随机偏移量的部分
if (!(imgp->ip_flags & IMGPF_DISABLE_ASLR)) {
//先计算整个section的大小和偏移量
vm_map_get_max_aslr_slide_section(map, &aslr_section_offset, &aslr_section_size);
aslr_section_offset = (random() % aslr_section_offset) * aslr_section_size;
//取一个随机数,模上最大可偏移页数,然后页对齐(就是乘以了页的大小)
aslr_page_offset = random();
aslr_page_offset %= vm_map_get_max_aslr_slide_pages(map);
aslr_page_offset <<= vm_map_page_shift(map);//页对齐,一个页的大小是2^page_shift
//这里计算方法和上面差不多
dyld_aslr_page_offset = random();
dyld_aslr_page_offset %= vm_map_get_max_loader_aslr_slide_pages(map);
dyld_aslr_page_offset <<= vm_map_page_shift(map);
//最后加上了整个section的偏移量
aslr_page_offset += aslr_section_offset;
}
//xxxxx…..
//调用parse_machfile来扫描文件和执行Load Command
lret = parse_machfile(vp, map, thread, header, file_offset, macho_size,
0, aslr_page_offset, dyld_aslr_page_offset, result,
NULL, imgp);
//xxxxxx…..
}
上面摘录了load_machfile部分函数代码(包含ASLR相关的部分)。
函数首先初始化了pmap,然后通过pmap创建了一个vm_map(vm_map是一段虚拟内存的入口,由一个vm_map_entry双向链表组成,最终映射到一系列vm_page。而映射到具体不同硬件的物理内存由pmap负责,后面会新开文章详细介绍Darwin的虚拟内存相关内容),该Mach-O文件内容会加载到这个vm_map中。
接着对于各个段的加载和动态库的加载分别计算了一个page_offset,具体的计算过程是先取一个随机数,然后跟最大的偏移页数取余,最后左移每个页的shift值进行页对齐(防止一个页里面有两个mach-o加载出来的东西等),最后加上整个section的offset,得到最终的偏移量。计算出来的偏移量会被用于parse_machfile。
2. parse_machfile执行Load Command
parse_machfile函数负责扫描各个段并执行相应的Load Command,先看看部分源码(也是只摘了一小部分,源码在mach_loader.c中):
static
load_return_t
parse_machfile(
struct vnode *vp,//这里面存着文件信息
vm_map_t map,//之前传进来的虚拟地址入口
thread_t thread,
struct mach_header *header,
off_t file_offset,
off_t macho_size,
int depth,
int64_t aslr_offset,//随机偏移量
int64_t dyld_aslr_offset,//针对动态库的随机偏移量
load_result_t *result,
load_result_t *binresult,
struct image_params *imgp
)
{
//获取vnode的”memory object control”,里面有具体的”pager”来获取真正的页(虚拟内存相关知识,后续详细介绍)
/*
* Get the pager for the file.
*/
control = ubc_getobject(vp, UBC_FLAGS_NONE);
//xxxxx….
//PIE(Position-independent executable),指代码的执行不依赖它的绝对地址
/*
* For PIE and dyld, slide everything by the ASLR offset.
*/
if ((header->flags & MH_PIE) || is_dyld) {
slide = aslr_offset;
}
//xxxxx…
/*
* Scan through the commands, processing each one as necessary.
* We parse in three passes through the headers:
* 0: determine if TEXT and DATA boundary can be page-aligned
* 1: thread state, uuid, code signature
* 2: segments
* 3: dyld, encryption, check entry point
*/
//四趟扫描,分别遍历Load Command
for (pass = 0; pass <= 3; pass++) {
//xxxxxx….
/*
* Loop through each of the load_commands indicated by the
* Mach-O header; if an absurd value is provided, we just
* run off the end of the reserved section by incrementing
* the offset too far, so we are implicitly fail-safe.
*/
offset = mach_header_sz;
ncmds = header->ncmds;
while (ncmds--) {
//xxxx..
/*
* Get a pointer to the command.
*/
lcp = (struct load_command *)(addr + offset);
oldoffset = offset;
//xxx….
/*
* Act on struct load_command's for which kernel
* intervention is required.
*/
switch(lcp->cmd) {
case LC_SEGMENT: {
//加载段
struct segment_command *scp = (struct segment_command *) lcp;
//xxxx…
ret = load_segment(lcp,
header->filetype,
control,
file_offset,
macho_size,
vp,
map,
slide,
result);
//xxxxx….
}
case LC_SEGMENT_64: {
//xxxx
}
case LC_UNIXTHREAD:
//开启一个unix线程,区别于LC_THREAD(加载一个mach线程,用于内核)
if (pass != 1)
break;
ret = load_unixthread(
(struct thread_command *) lcp,
thread,
slide,
result);
break;
case LC_MAIN:
//用于取代LC_UNIXTHREAD,主要用来加载主线程,设置entry point,栈大小等
//xxxx.
break;
case LC_LOAD_DYLINKER:
//加载动态库
if (pass != 3)
break;
if ((depth == 1) && (dlp == 0)) {
dlp = (struct dylinker_command *)lcp;
dlarchbits = (header->cputype & CPU_ARCH_MASK);
} else {
ret = LOAD_FAILURE;
}
break;
case LC_UUID:
if (pass == 1 && depth == 1) {
ret = load_uuid((struct uuid_command *) lcp,
(char *)addr + cmds_size,
result);
}
break;
//xxxxx…
}
//xxxx
}
}
}
可以看到这里总共分四趟扫描,每趟扫描去遍历head里所有的load command。第0趟检查TEXT段和DATA段是不是可以页对齐,第1趟加载线程(LC_UNIXTHREAD和LC_MAIN,加载主线程的entry point之类的),uuid以及代码签名相关命令,第2趟加载各个段(LC_SEGMENT),最后一趟加载动态库,进行加密等。
这里随机偏移量作为了load_segment,load_unixthread等具体加载各个段,线程等函数的slide参数。下面以load_segment为例。
3.load_segment 和 map_segment
这两个函数主要负责将一个段的内容映射到虚拟内存中去,做了很多内存对齐的工作,首先看一下load_segment的结构(用otool命令可查看):
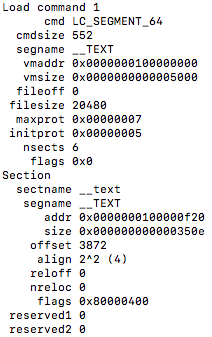
这里标明了他在文件中的偏移量,大小,虚拟地址的位置和大小等信息。看load_segment的源码之前先看几个用于内存对齐的宏定义(每个都有我的注释,大家安心看)
//page_shift,每个page的大小为2^shift
#define VM_MAP_PAGE_SHIFT(map) ((map) ? (map)->hdr.page_shift : PAGE_SHIFT)
#define VM_MAP_PAGE_SIZE(map) (1 << VM_MAP_PAGE_SHIFT((map)))
//page_mask,取page_size-1(如size是10000,那么mask是1111)
#define VM_MAP_PAGE_MASK(map) (VM_MAP_PAGE_SIZE((map)) - 1)
#define VM_MAP_PAGE_ALIGNED(x,pgmask) (((x) & (pgmask)) == 0)
//round对齐,用当前的offset加上一个mask,相当于向上取整,进一位(offset:10010,mask:1111,那么结果就是20000)
#define vm_map_round_page(x,pgmask) (((vm_map_offset_t)(x) + (pgmask)) & ~((signed)(pgmask)))
//trunc对齐,用当前的offset向下取整(offset:10010,mask:1111,那么结果就是10000)
#define vm_map_trunc_page(x,pgmask) ((vm_map_offset_t)(x) & ~((signed)(pgmask)))
上面几个虚拟内存相关的宏定义主要就是给定一个offset,把它调整到一个页的起始位置。接下来看一下load_segment和map_segment都干了些什么。
static
load_return_t
load_segment(
struct load_command *lcp,
uint32_t filetype,
void * control,
off_t pager_offset,
off_t macho_size,
struct vnode *vp,
vm_map_t map,
int64_t slide,
load_result_t *result)
{
struct segment_command_64 segment_command, *scp;
kern_return_t ret;
size_t segment_command_size, total_section_size,
single_section_size;
vm_map_offset_t file_offset, file_size;//文件中的偏移量和大小
vm_map_offset_t vm_offset, vm_size;//load_command里定义的虚拟地址偏移量和大小
vm_map_offset_t vm_start, vm_end, vm_end_aligned;//计算得到的该段实际的开始和结束地址
vm_map_offset_t file_start, file_end;//文件中的开始和结束偏移量,根据file_offset计算得到,其实file_offset必须是4K-alignment的
//实际用的page_size 和mask,取默认PAGE_SIZE和实际map中size的最大值
vm_map_size_t effective_page_size;
vm_map_offset_t effective_page_mask;
#if __arm64__
vm_map_kernel_flags_t vmk_flags;
boolean_t fourk_align;
#endif /* __arm64__ */
effective_page_size = MAX(PAGE_SIZE, vm_map_page_size(map));
effective_page_mask = MAX(PAGE_MASK, vm_map_page_mask(map));
//xxxx…
//判断是否需要4K-alignment(4k是默认的page_size),需要通过fourk_pager来对齐
if (LC_SEGMENT_64 == lcp->cmd) {
segment_command_size = sizeof(struct segment_command_64);
single_section_size = sizeof(struct section_64);
#if __arm64__
/* 64-bit binary: should already be 16K-aligned */
fourk_align = FALSE;
#endif /* __arm64__ */
} else {
segment_command_size = sizeof(struct segment_command);
single_section_size = sizeof(struct section);
#if __arm64__
/* 32-bit binary: might need 4K-alignment */
if (effective_page_size != FOURK_PAGE_SIZE) {
/* not using 4K page size: need fourk_pager */
fourk_align = TRUE;
verbose = TRUE;
} else {
/* using 4K page size: no need for re-alignment */
fourk_align = FALSE;
}
#endif /* __arm64__ */
}
//把lcp强转成具体命令
if (LC_SEGMENT_64 == lcp->cmd) {
scp = (struct segment_command_64 *)lcp;
} else {
scp = &segment_command;
widen_segment_command((struct segment_command *)lcp, scp);
}
//xxxxx…
//这里vm_offset用命令中指定的地址加上了之前传进来随机偏移量
vm_offset = scp->vmaddr + slide;
vm_size = scp->vmsize;
//xxxxx…
//根据是否要fourk_align来计算相应的vm_start和vm_end,本质上就是round和trunc的时候用的mask不同
#if __arm64__
if (fourk_align) {
//其实前面已经判断过file_offset是否已经是4K-alignment的了
/* 4K-align */
file_start = vm_map_trunc_page(file_offset,
FOURK_PAGE_MASK);
file_end = vm_map_round_page(file_offset + file_size,
FOURK_PAGE_MASK);
vm_start = vm_map_trunc_page(vm_offset,
FOURK_PAGE_MASK);
vm_end = vm_map_round_page(vm_offset + vm_size,
FOURK_PAGE_MASK);
if (!strncmp(scp->segname, "__LINKEDIT", 11) &&
page_aligned(file_start) &&
vm_map_page_aligned(file_start, vm_map_page_mask(map)) &&
page_aligned(vm_start) &&
vm_map_page_aligned(vm_start, vm_map_page_mask(map))) {
/* XXX last segment: ignore mis-aligned tail */
file_end = vm_map_round_page(file_end,
effective_page_mask);
vm_end = vm_map_round_page(vm_end,
effective_page_mask);
}
} else
#endif /* __arm64__ */
{
file_start = vm_map_trunc_page(file_offset,
effective_page_mask);
file_end = vm_map_round_page(file_offset + file_size,
effective_page_mask);
vm_start = vm_map_trunc_page(vm_offset,
effective_page_mask);
vm_end = vm_map_round_page(vm_offset + vm_size,
effective_page_mask);
}
//xxxxx….
//根据先前计算得到的几个偏移量,用map_segment进行映射
if (vm_size > 0) {
initprot = (scp->initprot) & VM_PROT_ALL;
maxprot = (scp->maxprot) & VM_PROT_ALL;
/*
* Map a copy of the file into the address space.
*/
ret = map_segment(map,
vm_start,
vm_end,
control,
file_start,
file_end,
initprot,
maxprot);
if (ret) {
return LOAD_NOSPACE;
}
//xxxx…….
}
return ret;
}
这里整体流程如下:
- 计算
effective_page_size和effective_page_mask,取默认值和Load Command中指定值两者中的最大值。 -
根据
effective_page_size是否等于FOURK_PAGE_SIZE来判断是否要强行通过fourk_pager来对齐。这里FOURK_PAGE_SIZE(FOURK = 4K的意思)就是4K大小,是默认的page大小。#define FOURK_PAGE_SIZE 0x1000 - 根据
effective_page_mask或者FOURK_PAGE_SIZE来trunc虚拟地址的起始值,round虚拟地址的结束值 - 用
map_segment来把文件内容(control参数里有文件的pager)映射到虚拟地址空间(map)里。 map_segment函数通过vm_map_enter_mem_object_control来向map里插入一个map_entry,把具体segment的内容映射成vm_object和vm_page。
这里涉及到了一些具体的虚拟内存的管理,只简单介绍了一些概念,后续会开新的文章详细介绍虚拟内存相关内容。
参考文献:
【1】Darwin-XNU源码:https://github.com/apple/darwin-xnu
【2】Mac OS® X and iOS Internals: http://newosxbook.com/MOXiI.pdf
【3】Mach-O Runtime Architecture: http://math-atlas.sourceforge.net/devel/assembly/MachORuntime.pdf