Image Inpainting
An algorithm help you remove stamps in images.
Demo
Algorithm
Image pinpointing algorithms can be mainly decided into 3 categories: structural inpainting, textural inpainting and mixed inpainting. The algorithm used in this application is a texture based inapinting algortihm[1].
General Idea
To find map between pixels in the stamp region and pixels in other parts. Then use the color of F(α) to fill pixel α.
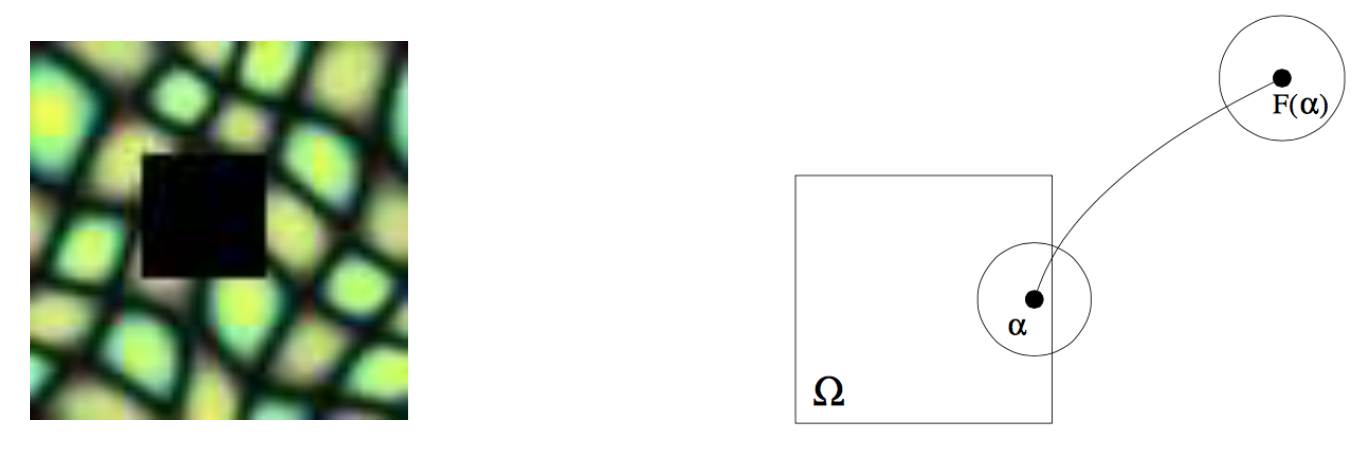
Neighborhood matching.
Find the best pixel among candidates depends on their neighborhoods.
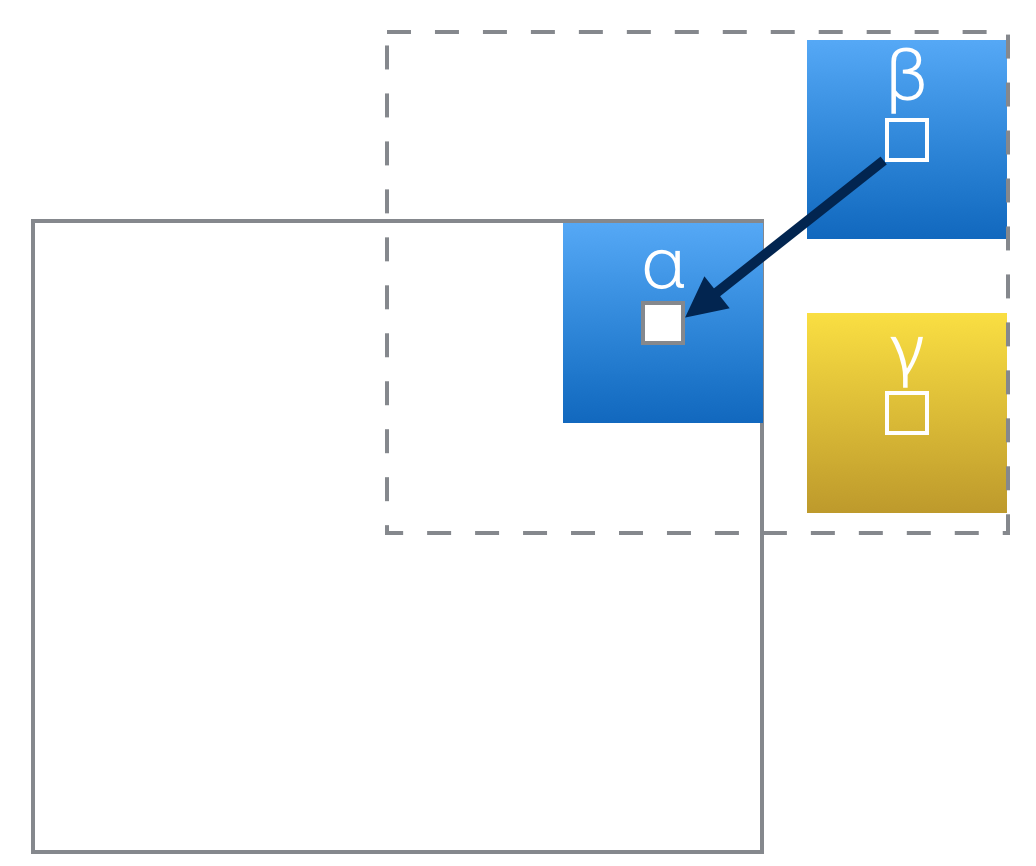
The “Match Rate” between origin and a candidate pixel is the Euclidian distance between them
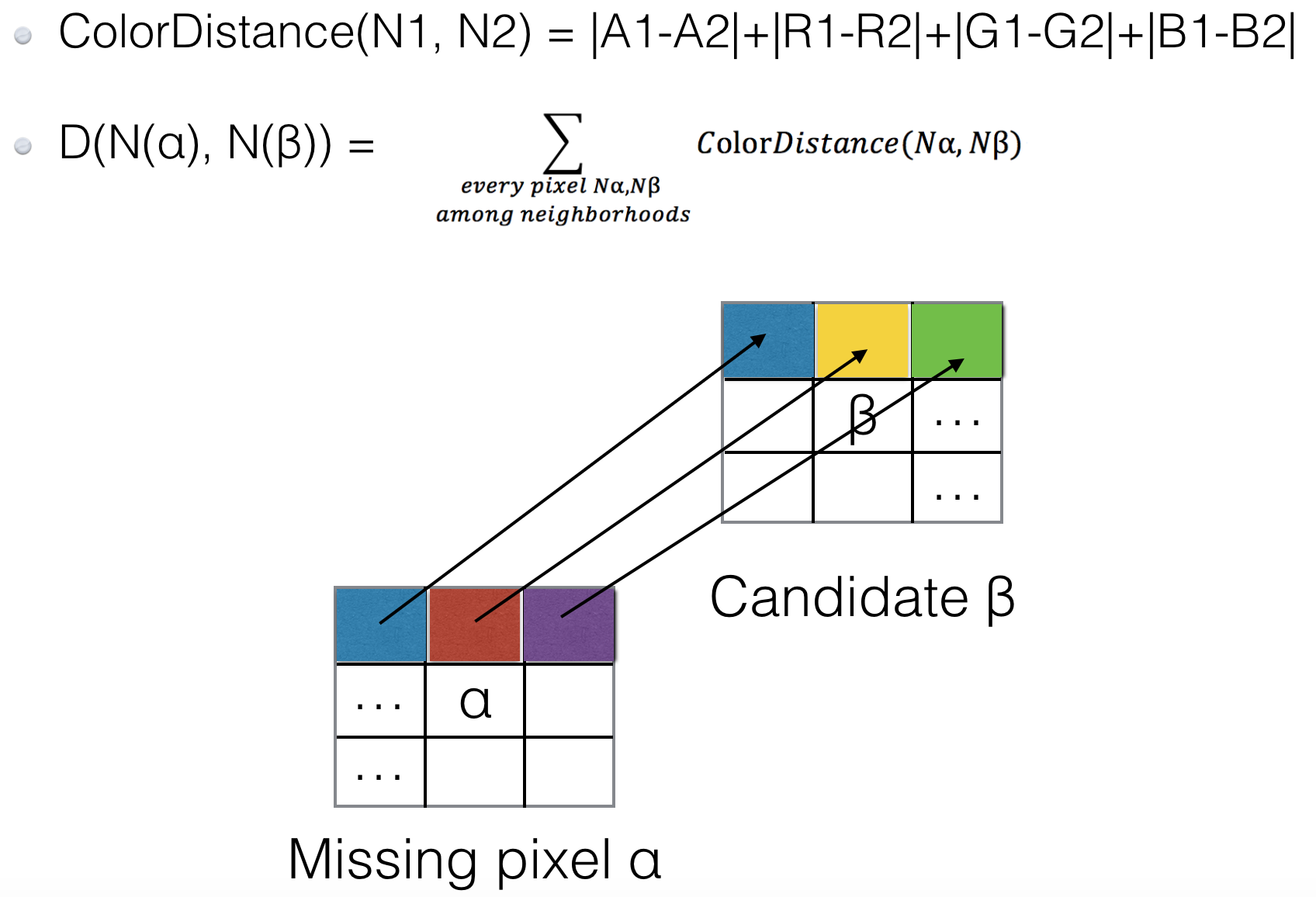
###
In order to store the stamp region, I use pixel range of each pixel row to represent a irregular region.
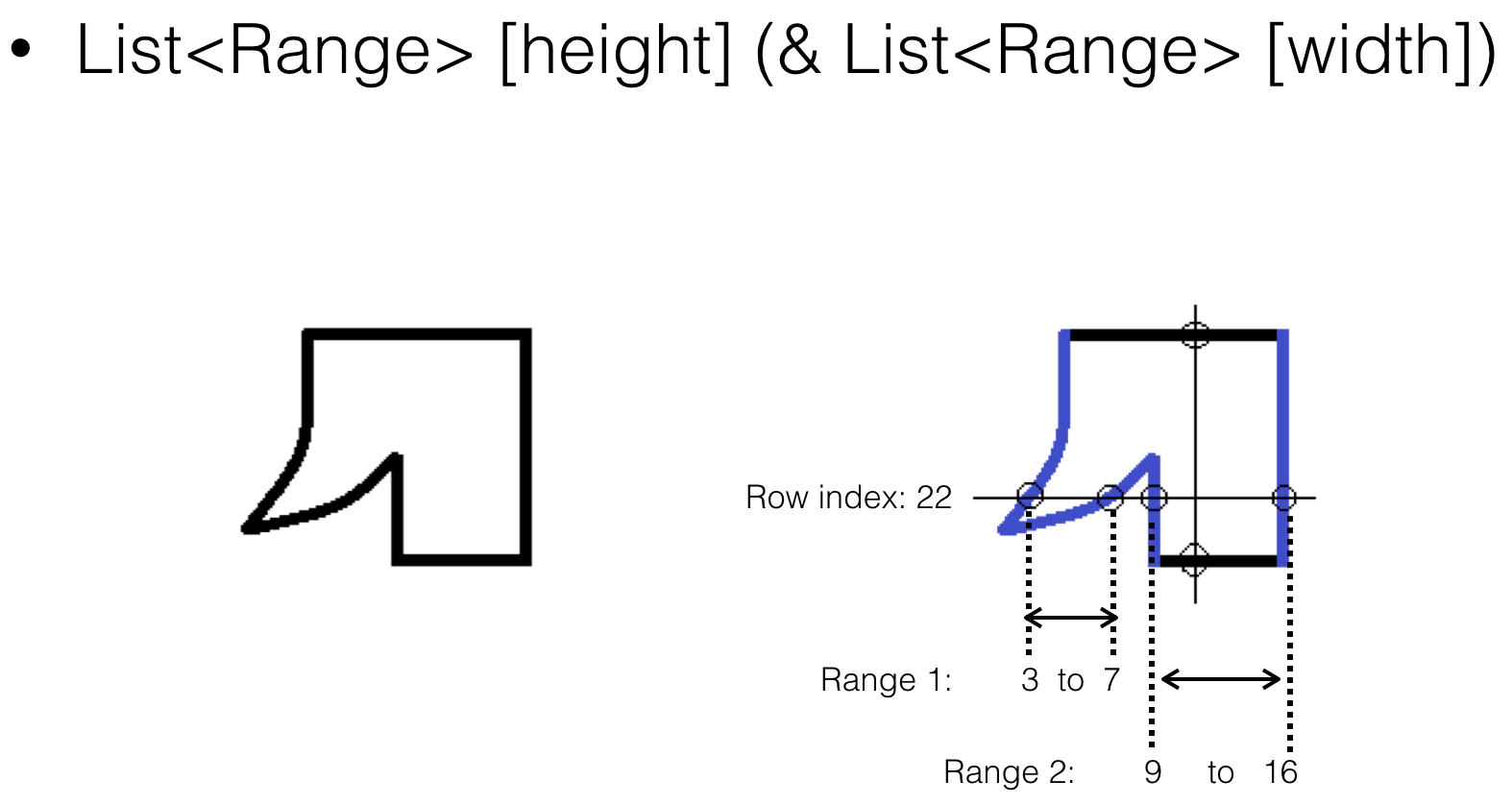
Improvement
Same neighborhoods
As an example, when the algorithm is looking for the best pixel among candidates, one situation is below.
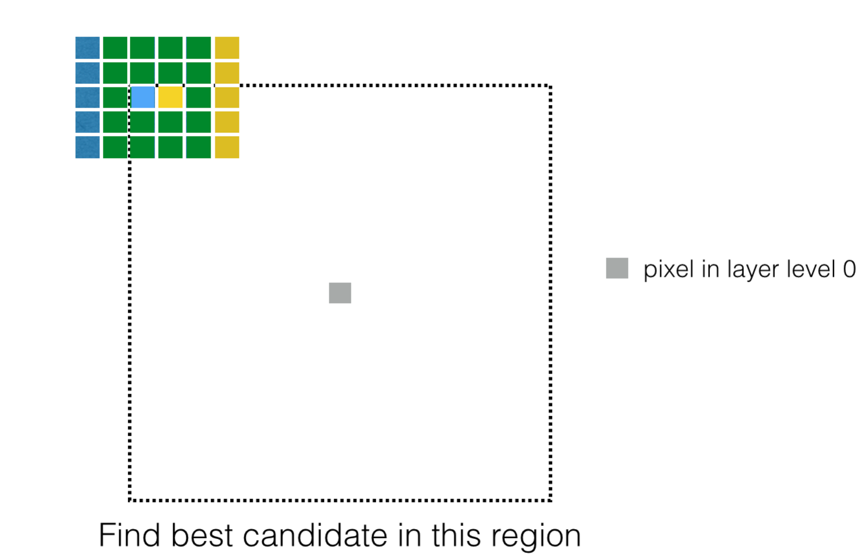
The Grey pixel is in the missing region and it’s on the circular layer 0. The blue pixel and the yellow pixel are its two possible candidates. It’s obviously that these two candidates have a big part of same neighborhoods – four green columns.
</br>
It can be a possible point where duplicate calculation happens since they have “same” neighborhoods. But are there really have duplicate calculations when calculate the Euclidian distance between these two candidates and the source pixel in the missing region? The answer is “NO”.
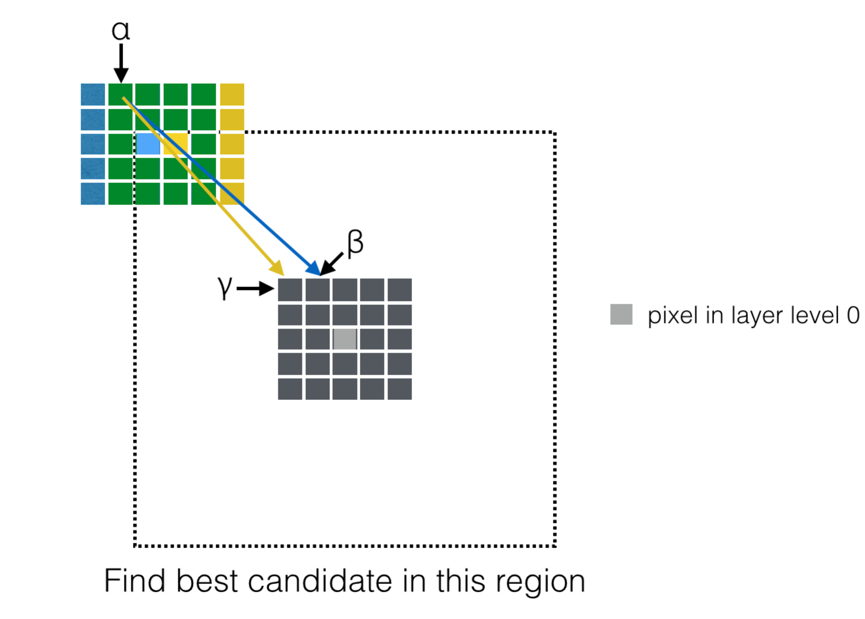
As an example, consider the public neighborhood pixel α. When the algorithm calculates the Euclidian distance between the blue pixel and the grey pixel, neighborhood pixel α will be compared with the pixel β. However, when it turns to the calculation of the Euclidian distance between the yellow pixel and the grey pixel, α will compare with γ.
Calculation legacy
We have already found that there are a big part of same neighborhoods between two closed candidate pixels. However, these same neighborhoods will all be compared with different pixels of neighborhoods of the source pixel in the missing region.
For each source pixel in the missing region, this algorithm will find the best candidate among those pixels near the source pixel. And for each possible pair, the algorithm should calculate the Euclidian distance between two pixels. So it becomes a time costing procedure to find out the best pixel among candidates.
As mentioned before, for one pixel in the missing region, when looking for its best candidate, there is no duplicate calculation. But how it will be if we consider more pixels in the missing region?
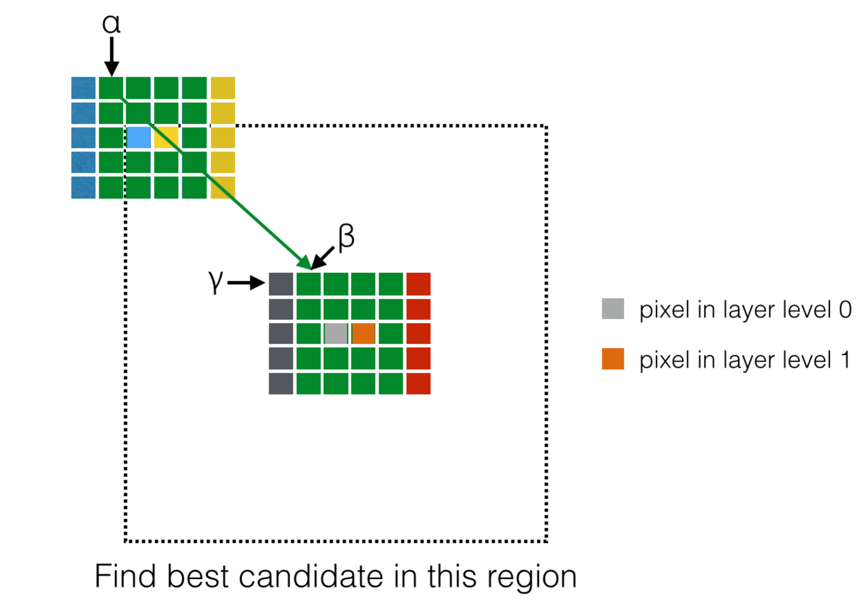
Considering a new pixel in the missing region. The red pixel is near the grey pixel and it’s in layer level 1. It’s obviously that the red pixel and the grey pixel have four same neighborhood columns.
</br>
When we calculate the Euclidian distance between the grey pixel and the blue pixel, pixel α will be compared with pixel β. And when we calculate the Euclidian distance between the red pixel and the yellow pixel, the pixelα will be also compared with pixel β. For all the pixels in four same neighborhood columns, calculations for the pixel in the layer level 0 are the same as those for the layer level 1. So for each pixel row in the missing region, pixels in smaller layer level can generate “calculation legacy” to pixels in bigger layer level.
</br>
It’s better to restore the calculate result of each column when implementing this feature. Since with the growth of layer level, new columns will be add in and old columns will be removed. The implementation is complicate since we need to restore different calculation legacy for each pixel row and each candidate row.
</br>